分析数据
Tier0 采用 Marimo Notebook,支持使用 Python 进行高级数据分析。
创建 Notebook
- 登录 Tier0,然后选择 Notebook。
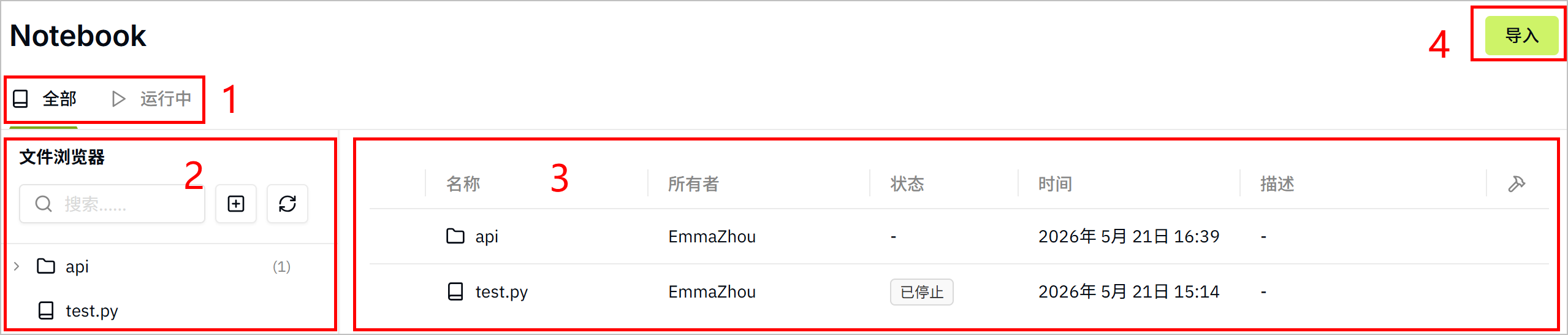
| 编号 | 项目 | 说明 |
|---|---|---|
| 1 | 分类 | 按状态显示 Notebook。 |
| 2 | Notebook 树图 | 以文件夹-文件层级结构列出 Notebook,支持添加 Notebook、刷新列表和搜索 Notebook。 |
| 3 | Notebook 列表 | 详细显示所选文件夹下的所有 Notebook。 |
| 4 | 导入 | 导入 Notebook。 |
- 选择
 > 新建文件夹。
> 新建文件夹。
- 输入文件夹名称,然后单击 创建。
- 单击已创建的文件夹,然后选择 > 新建 Notebook。
- 输入 Notebook 信息,然后单击 创建。
- 单击右侧已创建的 Notebook,开始编辑。
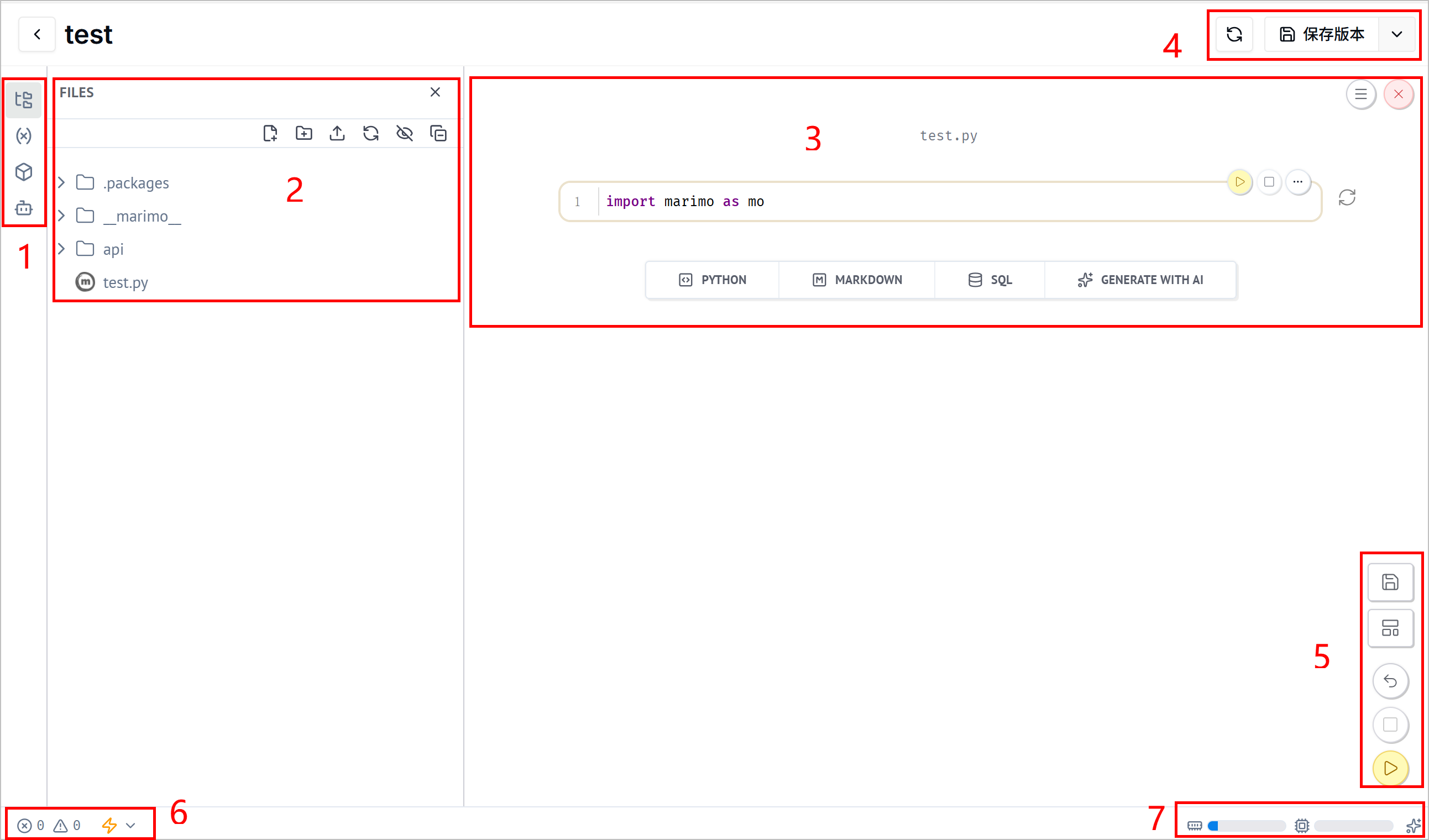
| 编号 | 项目 | 说明 |
|---|---|---|
| 1 | 模块 | 显示 Notebook 模块,包括数据源和变量、依赖包以及 AI 机器人。 |
| 2 | 文件 | 显示 Notebook 层级结构。 |
| 3 | 画布 | 显示单元格及对应结果。你可以选择创建不同类型的单元格、关闭 Notebook,以及修改 Notebook 设置。 |
| 4 | 工具栏 | 刷新单元格,并将 Notebook 保存为不同版本。 |
| 5 | Notebook 操作 | 保存 Notebook。切换当前查看样式,包括单元格与结果或仅结果。停止或运行所有单元格。 |
| 6 | 开发者模式 | 进入开发者面板,并设置运行时活动。 |
| 7 | 状态 | 显示内存、CPU 和 AI 状态。 |
使用 Notebook 执行 SQL 查询
开始前须知
UNS 存储到数据库中的数据会作为 Notebook 中已有的数据源。
- 登录 Tier0,然后选择 Notebook。
- 创建并进入一个 Notebook,单击左侧的 VARIABLES。
- 在左侧找到需要的表,单击表名旁边的
 ,自动生成 SQL 语句。
,自动生成 SQL 语句。
- 单击右下角的
 ,运行所有单元格并查看查询结果。
,运行所有单元格并查看查询结果。
提示
- 你可以单击左侧 DATA SOURCES 下的
 ,按需添加数据源。
,按需添加数据源。 - 使用 Notebook 时可能缺少部分依赖包。此时,单击左侧的 Manage packages 进行安装。
- (可选)单击 SQL 添加新的单元格,然后选择已连接的数据库执行 SQL 语句。

使用 Notebook 分析数据
示例背景
- 数据源是从工厂采集并发送到 Tier0 UNS 的设备温度和湿度。
- 数据分析内容包括设置温湿度风险阈值、根据温湿度的组合数据识别风险,并生成表格和图表,便于查看。
操作步骤
- 登录 Tier0,然后选择 Notebook。
- 创建一个 Notebook,并在其中添加以下单元格。
- 单元格 1:导入库。
import marimo as mo
import pandas as pd
import altair as alt
- 单元格 2:从数据库查询数据。
SELECT * FROM "uns"."device_15d9d69fd5eb" LIMIT 100
- 单元格 3:清洗数据。
# 将SQL查询结果转成 pandas DataFrame
if hasattr(device_df, "to_pandas"):
df = device_df.to_pandas()
elif hasattr(device_df, "to_dicts"):
df = pd.DataFrame(device_df.to_dicts())
else:
df = pd.DataFrame(device_df)
# 清洗并准备数据
df["_timestamp"] = pd.to_datetime(df["_timestamp"])
df = df.sort_values("_timestamp").reset_index(drop=True)
df["temp"] = pd.to_numeric(df["temp"], errors="coerce")
df["humidity"] = pd.to_numeric(df["humidity"], errors="coerce")
df = df.dropna(subset=["temp", "humidity"])
df.head()
- 单元格 4:设置风险阈值并生成风险状态字段。
temp_warning = mo.ui.slider(
start=0,
stop=100,
value=70,
label="Temperature warning threshold",
)
temp_critical = mo.ui.slider(
start=0,
stop=100,
value=85,
label="Temperature critical threshold",
)
humidity_warning = mo.ui.slider(
start=0,
stop=100,
value=70,
label="Humidity warning threshold",
)
humidity_critical = mo.ui.slider(
start=0,
stop=100,
value=85,
label="Humidity critical threshold",
)
mo.vstack([
mo.md("## Threshold Settings"),
mo.hstack([temp_warning, temp_critical]),
mo.hstack([humidity_warning, humidity_critical]),
])
- 单元格 5:根据单元格 4 中设置的阈值,生成包含风险状态和异常状态的表格。
analyzed_df = df.copy()
def classify_risk(row):
temp = row["temp"]
humidity = row["humidity"]
temp_high = temp >= temp_warning.value
temp_critical_high = temp >= temp_critical.value
humidity_high = humidity >= humidity_warning.value
humidity_critical_high = humidity >= humidity_critical.value
if temp_critical_high and humidity_critical_high:
return "Critical: High temp + high humidity"
elif temp_critical_high:
return "Critical: High temperature"
elif humidity_critical_high:
return "Critical: High humidity"
elif temp_high and humidity_high:
return "Warning: Combined risk"
elif temp_high:
return "Warning: Temperature risk"
elif humidity_high:
return "Warning: Humidity risk"
else:
return "Normal"
analyzed_df["risk_status"] = analyzed_df.apply(classify_risk, axis=1)
analyzed_df["is_anomaly"] = analyzed_df["risk_status"] != "Normal"
analyzed_df.head()
- 单元格 6:生成异常汇总统计信息。
total_count = len(analyzed_df)
anomaly_count = analyzed_df["is_anomaly"].sum()
normal_count = total_count - anomaly_count
anomaly_rate = anomaly_count / total_count * 100 if total_count > 0 else 0
critical_count = analyzed_df["risk_status"].str.startswith("Critical").sum()
warning_count = analyzed_df["risk_status"].str.startswith("Warning").sum()
mo.vstack([
mo.md("## Joint Anomaly Detection Summary"),
mo.hstack([
mo.stat(label="Total Records", value=f"{total_count}"),
mo.stat(label="Normal Records", value=f"{normal_count}"),
mo.stat(label="Warning Records", value=f"{warning_count}"),
mo.stat(label="Critical Records", value=f"{critical_count}"),
mo.stat(label="Anomaly Rate", value=f"{anomaly_rate:.1f}%"),
])
])
- 单元格 7:生成柱状图,显示不同风险状态的分布。
risk_summary = (
analyzed_df
.groupby("risk_status")
.size()
.reset_index(name="count")
.sort_values("count", ascending=False)
)
risk_bar_chart = alt.Chart(risk_summary).mark_bar().encode(
x=alt.X("count:Q", title="Record Count"),
y=alt.Y("risk_status:N", sort="-x", title="Risk Status"),
tooltip=["risk_status", "count"]
).properties(
title="Risk Status Distribution",
width=700,
height=300
)
risk_bar_chart
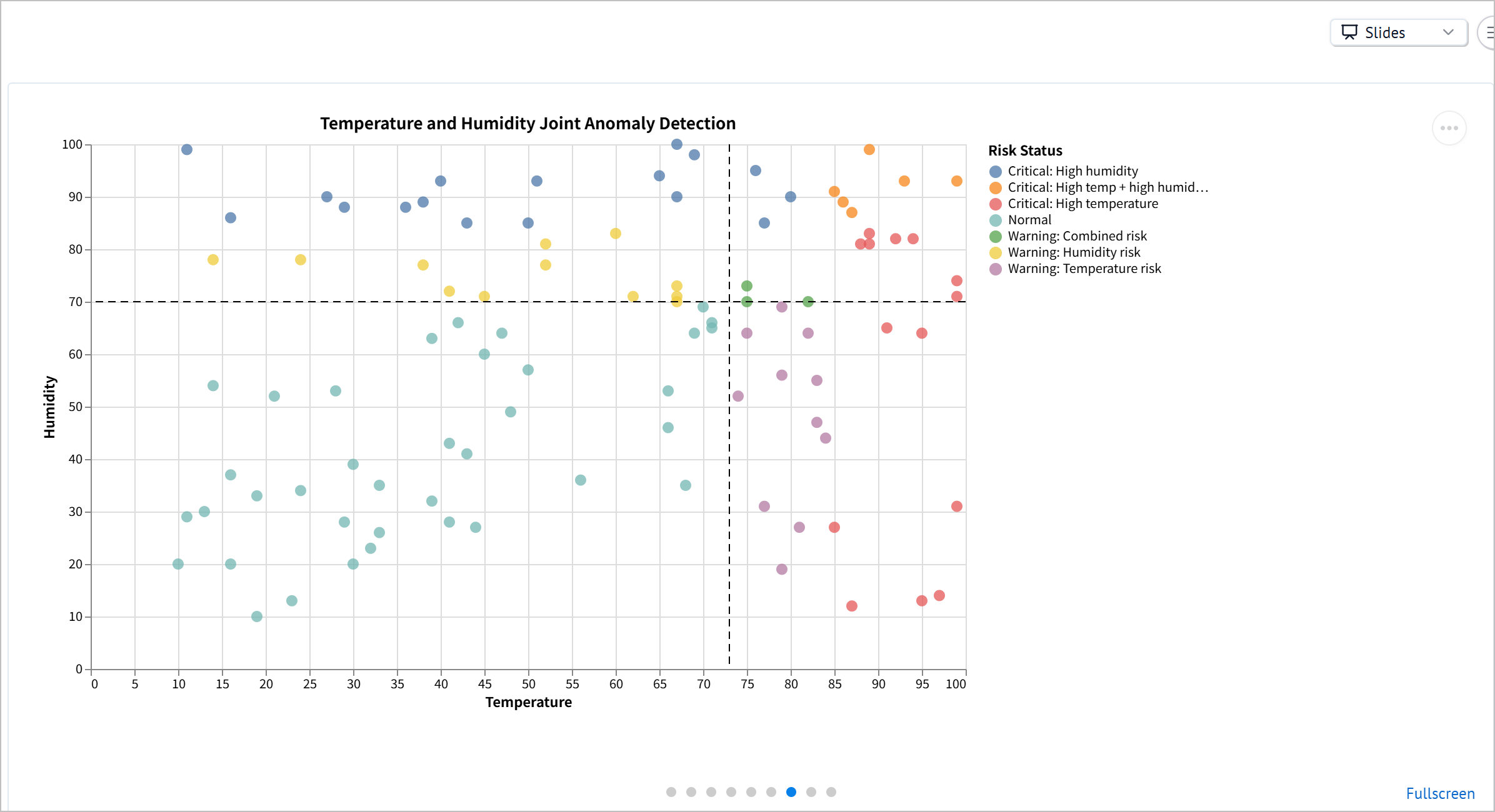
- 单元格 8:生成散点图,显示温度和湿度之间的关系,并按风险状态区分点的颜色。
scatter_chart = alt.Chart(analyzed_df).mark_circle(size=80, opacity=0.75).encode(
x=alt.X("temp:Q", title="Temperature"),
y=alt.Y("humidity:Q", title="Humidity"),
color=alt.Color("risk_status:N", title="Risk Status"),
tooltip=[
alt.Tooltip("_timestamp:T", title="Timestamp"),
alt.Tooltip("temp:Q", title="Temperature"),
alt.Tooltip("humidity:Q", title="Humidity"),
alt.Tooltip("risk_status:N", title="Risk Status"),
],
).properties(
title="Temperature and Humidity Joint Anomaly Detection",
width=700,
height=420,
)
temp_warning_line = alt.Chart(pd.DataFrame({"x": [temp_warning.value]})).mark_rule(
strokeDash=[6, 4]
).encode(
x="x:Q"
)
humidity_warning_line = alt.Chart(pd.DataFrame({"y": [humidity_warning.value]})).mark_rule(
strokeDash=[6, 4]
).encode(
y="y:Q"
)
scatter_chart + temp_warning_line + humidity_warning_line
- 单元格 9:生成表格,显示异常记录详情。
anomaly_df = analyzed_df[analyzed_df["is_anomaly"]].copy()
anomaly_df = anomaly_df[
["_timestamp", "temp", "humidity", "risk_status"]
].sort_values("_timestamp")
mo.vstack([
mo.md("## Anomaly Details"),
mo.md(f"Detected **{len(anomaly_df)}** abnormal records based on the current thresholds."),
mo.ui.table(anomaly_df, page_size=10),
])
- 单元格 10:生成分析结论摘要。
most_common_risk = (
risk_summary.iloc[0]["risk_status"]
if len(risk_summary) > 0
else "N/A"
)
mo.md(f"""
## Analysis Conclusion
Based on the current threshold settings:
- Total records analyzed: **{total_count}**
- Abnormal records detected: **{anomaly_count}**
- Overall anomaly rate: **{anomaly_rate:.1f}%**
- Warning records: **{warning_count}**
- Critical records: **{critical_count}**
- Most common status: **{most_common_risk}**
This analysis uses both temperature and humidity to identify equipment environment risks.
Compared with single-threshold monitoring, joint anomaly detection can better identify combined environmental risks, such as high temperature and high humidity occurring at the same time.
""")
- 单击右下角的 ,运行所有单元格并查看结果。
提示
在右上角的 Vertical、Grid 和 Slides 中切换查看样式。